Our Approach
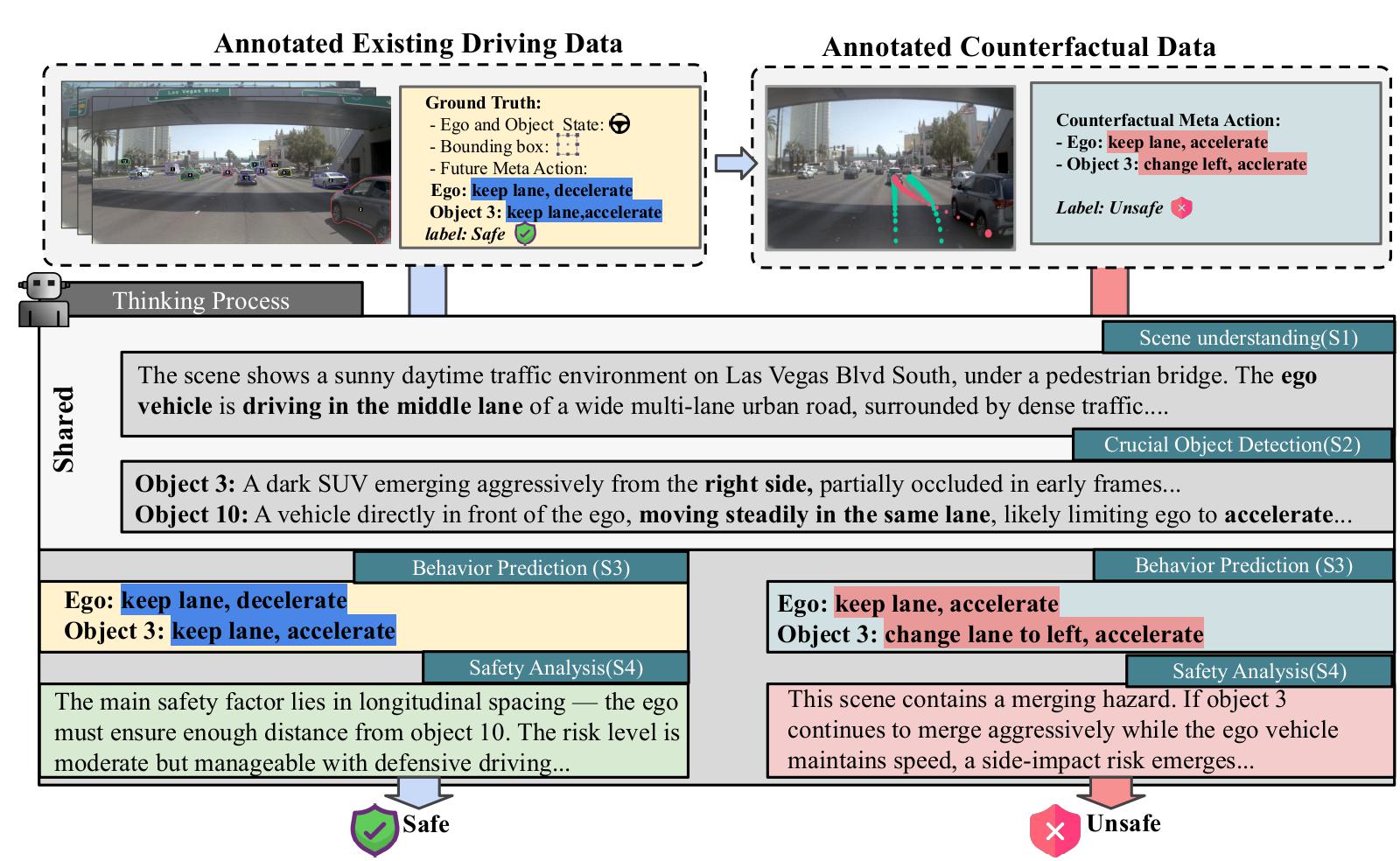
SafeVL performs structured, interpretable reasoning over real and counterfactual driving scenarios to evaluate safety in autonomous driving. The framework first employs a Road-Graph Counterfactual Data Generation Engine that perturbs agent actions such as acceleration and lane changes to synthesize diverse unsafe outcomes. This process expands the range of rare yet critical collision-prone scenarios. Then, an Object-centric Visual Reasoning Framework processes each driving video through four stages: (S1) scene understanding, (S2) key object detection, (S3) behavior prediction for ego and surrounding agents, and (S4) safety analysis. By aligning safe trajectories with their counterfactual unsafe variants under the same reasoning pipeline, SafeVL learns to identify and explain high-risk events before collisions occur, producing transparent and reliable Safe/Unsafe decisions.